Prompt 寫了卻還是不穩:用三組實驗看完成判定該放在哪裡
上一篇文章〈Prompt 已經寫很細了,Workflow 為什麼還是不穩?〉談到,多步驟 agent workflow 常見的三種失靈:過早開始、假性完成、未驗證即結案。這三種現象,最後都會回到同一個控制問題:「完成」到底由誰判定。
當 workflow 的成敗開始取決於真實狀態、工具結果或驗證條件時,只把完成條件寫在 prompt 裡,通常是不夠的,得交給 prompt 以外的機制。
口說無憑。這篇文章想用一組小實驗看一件事:同一個任務、同一份 prompt,如果把「完成判定」放在不同位置,false completion 會怎麼變化?
我選了一個很小、但實務上很常遇到的任務:整理技術文章的註腳。
實驗任務
註腳重排要怎麼算完成
我在寫技術文章時,常會用註腳標出參考文獻。不過在定稿前,正文和參考文獻常常會反覆調整;一來一回之後,正文引用順序和文末定義順序很容易亂掉,也常會出現缺漏或重複。手動修不難,但很煩。
例如下面這篇短文:
這是第一段。[^3]
這是第二段。[^1]
這是第三段。[^4]
[^1]: 第一個註腳。
[^2]: 這個註腳沒有被引用。
[^3]: 第三個註腳。這裡至少有三個錯誤:
- 正文引用順序錯亂:數字大的
[^3]不該出現在[^1]前面。 - 有引用但沒有定義:正文標了
[^4],文末沒有對應的[^4]:。 - 有定義但沒有引用:文末有
[^2]:,正文沒有用到[^2]。
整理後應該變成這樣:
這是第一段。[^1]
這是第二段。[^2]
這是第三段。[^3]
[^1]: 第三個註腳。
[^2]: 第一個註腳。
[^3]: 這個註腳有引用但沒有定義。
<!-- 已移除未引用的註腳:
- 這個註腳沒有被引用。
-->
「把文件改到好」,實際上要處理很多細節;但「有沒有改好」相對起來比較好判斷。
只要寫一個 checker 小工具,檢查有引用但沒有定義、有定義但沒有引用、重複定義、引用順序與定義順序,最後回傳:
{
"pass": true
}或:
{
"pass": false,
"missing_definitions": ["4"], // 有引用但沒有定義
"unused_definitions": ["2"], // 有定義但沒有引用
"reference_order_errors": [...] // 引用或定義順序錯誤
}這個 checker 不需要很複雜(甚至可能只到 LeetCode 的 easy 程度)。有了它,Markdown 到底有沒有修好,就不必靠模型自己說了算。它就是這次實驗的外部判定者。
測試資料
實驗還需要一組合適的測試資料。
我準備了 10 份測資,刻意涵蓋幾種常見錯誤:
| # | 缺陷 |
|---|---|
case_01 |
引用順序錯亂、有引用無定義、有定義無引用 |
case_02 |
重複定義 |
case_03 |
定義區順序錯亂 |
case_04 |
多個缺漏定義 |
case_05 |
多餘的未使用定義 |
case_06 |
非連續編號 |
case_07 |
同一 footnote 多次引用(已合法,無須修改) |
case_08 |
正文無 ref,殘留 def |
case_09 |
含 URL 的 def,引用順序錯亂 |
case_10 |
混合缺陷(亂序、重複、缺漏、未使用) |
修改前與修改後的對照表,可見實驗 repo 的 docs/cases.md 文件。
其中三個 case 特別值得一提。
case_07 是對照組。 它原本就是合法的,正確回應是不改。模型如果為了交差多動一刀,checker 會抓到。
case_10 是混合題。 亂序、重複、缺漏、未使用四種缺陷同時存在,模型得把整套修正策略都做對才會過關。
case_06 最能看出問題。 技術上來說 Markdown 不要求註腳一定連續編號,甚至不用數字也可以,所以 [^1] 後面接 [^3] 不必然算錯;但這次實驗的 checker 規則更嚴,要求重新排成連續編號,因為這才比較符合一般讀者的直覺。
實驗設計
這三組實驗的主體 prompt 完全相同,只改一件事:completion gate 放在哪裡。
控制變因
要把文件改到好,不只是改一輪編號,而是一組相互依賴的步驟:
- 重新整理正文裡的註腳引用。
- 確認每個引用都有對應的定義。
- 移除沒有被引用的註腳定義。
- 避免重複定義。
- 讓正文引用順序與定義順序一致。
- 最後確認通過檢查,才算完成。
這些步驟在三組實驗裡都相同。
操縱變因:completion gate 放在哪裡
這次要測的是:當完成條件已經寫成外部 checker 的規則時,模型會不會真的照那個規則走,還是最後仍然用自己的語言判讀來放行。
三組實驗如下:
| 實驗 | 呼叫 tool? | read back? | 完成判定放在哪裡? |
|---|---|---|---|
實驗一:prompt_only |
否 | 否 | 模型自我宣告 |
實驗二:tool_no_readback |
是 | 否 | 模型知道工具被呼叫,但不知道結果 |
實驗三:tool_with_readback |
是 | 是 | checker result + gate |
實驗一最單純:只給模型 prompt,不准呼叫 checker。模型只能自己檢查自己。
實驗二刻意只做半套:模型必須呼叫 checker,但 checker 只回傳 accepted/run_id,不回傳真正的 pass/fail。這組對照,是想測試一個常見的假說:把任務拆成幾個 phase,要求模型每做完一段就輸出一個 marker、summary 或 artifact,流程是不是就比較不容易亂掉。
這種做法在互動式使用裡確實有幫助,因為中間輸出讓人看得見流程,也比較容易人工介入。但在這個實驗裡,重點不只是「有沒有留下東西」,而是那個東西有沒有真的被拿來判斷完成與否。
tool_no_readback 測的就是這個差別。它有呼叫外部工具,也有拿到一些無關痛癢的周邊資訊;但真正關鍵的 pass/fail 沒有回到流程裡。最後仍然是由模型自己決定能不能宣告 completed。
實驗三才是真的把 completion gate 移出去:模型必須呼叫 checker、讀回完整結果,再依照 pass/fail 決定能不能宣告 completed。pass=false 就得修正後重跑,pass=true 才能放行。
同一個任務裡,差別就在這裡:完成判定有沒有真的離開語言層。
實驗結果
實驗使用本機已登入的 Claude Code CLI 與 Codex CLI 執行。1
3 個 experiments * 10 個 cases,每個 case 都在獨立 workspace 中執行,最後由評分器 (grader) 呼叫 checker 判定結果。
以下是兩家旗艦款模型的結果。
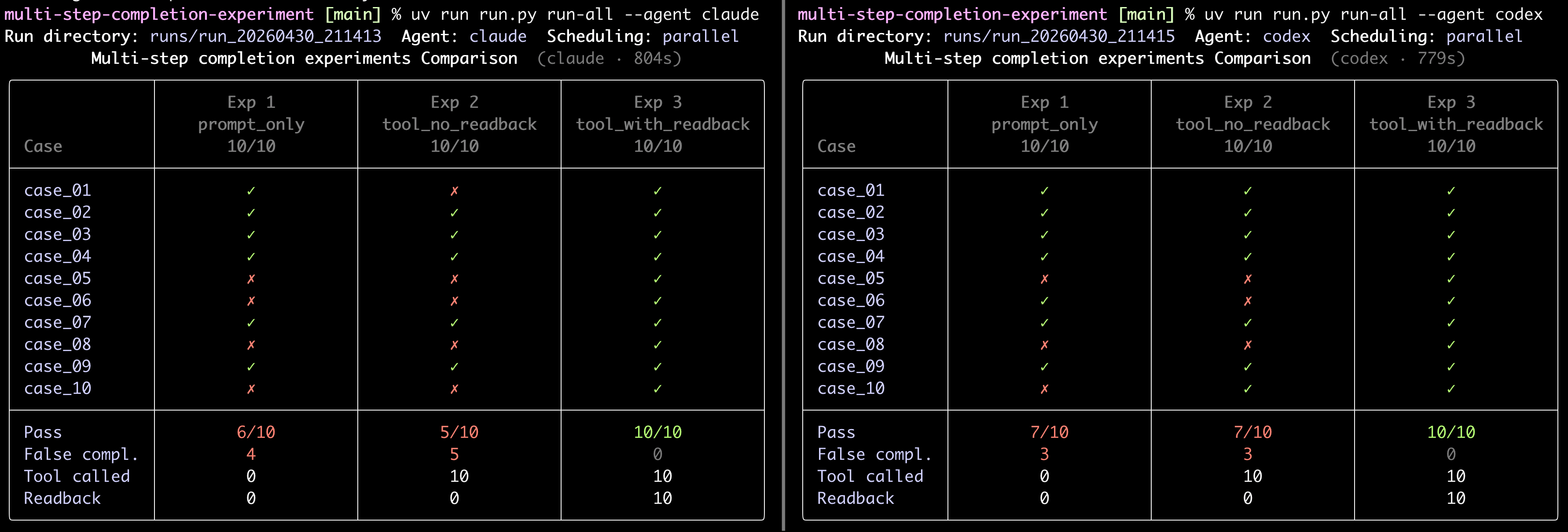
Claude Code CLI 的實驗結果
| Experiment | Actual Pass | False Completion | Tool Called | Readback Used |
|---|---|---|---|---|
| prompt_only | 6 | 4 | 0 | 0 |
| tool_no_readback | 5 | 5 | 10 | 0 |
| tool_with_readback | 10 | 0 | 10 | 10 |
prompt_only 出現 40% false completion。10 個 case 裡有 4 個是 AI 宣稱 completed,但最終 checker 判失敗;失敗的是 case_05、case_06、case_08、case_10。
到了 tool_no_readback,Claude 又多失敗一個 case_01,false completion 升到 50%。模型確實有呼叫 checker,但沒有讀回真正的檢查結果;這次呼叫不只沒幫上忙,還讓 case_01 偏移成 false completion。
到了 tool_with_readback,Claude 100% 通過,false completion 降到 0。就這組任務來看,只讓模型「有呼叫工具」不夠;checker 結果真的成為 gate,才有差別。
Codex CLI 的實驗結果
| Experiment | Actual Pass | False Completion | Tool Called | Readback Used |
|---|---|---|---|---|
| prompt_only | 7 | 3 | 0 | 0 |
| tool_no_readback | 7 | 3 | 10 | 0 |
| tool_with_readback | 10 | 0 | 10 | 10 |
Codex 在 prompt_only 跑出 7 / 3(actual pass / false completion)的結果;失敗的 3 個 case 是 case_05、case_08、case_10。
到了 tool_no_readback,Codex 仍然是 7 / 3,但失敗的 case 換了:case_10 這次過了,改成 case_06 失敗。也就是說,call tool 這個動作對行為有些微影響,但沒有提升完成判定的可信度。
跟 Claude 對照也看得到類似現象:Claude 在 prompt_only 失敗 4 個 case,到 tool_no_readback 又多失敗一個 case_01。兩個 agent 的偏移方向不一樣,但有一點相同:沒有 readback 時,false completion 都還在;接上 readback gate 後,兩邊都變成 10/10。
這不是在評比語言模型,也不是說所有 agent 都會跑出完全一樣的數字。但至少在這組任務上,有個很明顯的趨勢:只要「完成」的判定還留在模型自述裡,就容易遇到假性完成;一旦移交給外部 checker,結果就明顯收斂。
case_06:模型把局部合理的解釋當成完成
我用 case_06 來說明 prompt_only 的盲區:
第一段。[^1]
第二段。[^3]
[^1]: 第一個註腳。
[^3]: 第三個註腳。從 Markdown 規格的角度看,這份文件的 ref 和 def 是完整配對的:兩個 ref 都有對應 def、沒有 unused def,也沒有重複定義;只是編號不連續,跳過了 [^2]。
Claude 在 prompt_only 模式下讀完後,在 notes 裡留下這樣的判斷:
Input has no defects in any of the five recognised categories (
missing_definitions,unused_definitions,duplicate_definitions,reference_order_errors,definition_order_errors). The label gap between 1 and 3 is not itself a defect — footnote labels are identifiers, not sequence positions.
所以它保留原文,直接宣告 completed。
這個判讀其實是有道理的。就 Markdown 規格來說,footnote label 確實比較像 identifier,不一定代表順序位置。問題在於:這次實驗的 checker 規則更嚴,要求註腳重新排成連續編號。
同樣的 case_06,但 Codex 在 prompt_only 模式下反而會把 [^1]/[^3] 改成 [^1]/[^2],順利過關。也就是說,同一個任務、同一份 prompt,兩個 agent 在邊界條件上做出了不同解釋。
這正是 prompt_only 脆弱的地方。當「到底要不要修」本身就是一個判斷題,而判斷依據又散在 prompt 各處時,模型很容易找到一條對自己比較寬鬆的解釋路徑,然後把那個局部合理的解釋,當成整個 workflow 裡的完成判定。
至於 tool_with_readback 這做法,其實沒有讓模型突然更懂 Markdown;它只是把放行權從語言模型身上移走。若 checker 說 pass=false,流程就不能結案;得一直修到 pass=true 為止。
邊界條件:本機小模型 (Qwen3 系列)
我再用兩個 Qwen3 系列模型重做這組實驗:Qwen3:8b (general dense),以及 2026/02 發布的下一代 Qwen3.5-9B (hybrid 架構),把 Claude Code CLI 直接接到本機 Ollama。
兩個模型的工具呼叫能力都沒問題。但放進 Claude Code 整套 harness 去跑實驗,結果兩個模型都沒有任何一次真實的呼叫工具,失敗方式也完全不同。
在 Qwen3:8b 的實驗裡,每一個 case 都是 agent failure。不只是「沒寫檔」,也根本沒有真的呼叫任何工具。模型自己把整套 readback 流程都在想像中「演」完了,它甚至從 prompt 路徑裡抓到 workspace 名稱的字串,順手填進 run_id 欄位。夠聰明吧!
8B 失敗的原因是「決策被淹沒」。當 prompt 長到一個程度、工具選項多到一個程度,模型會跳過 tool-use 那個分支,直接退化成「產出一段看起來像答案的文字」就交差。能力沒消失,只是被擠出有效 attention 的範圍。2 從假性完成的角度看,這個結果其實比 Claude/Codex 的 30–50% 還糟:表面看像 100% 通過 (vacuous pass),實際上 100% 沒做事。
至於 Qwen3.5-9B,inference 真的有在跑,只是 token 產出速率崩潰到實務上完全不可用——Claude Code 這樣的 harness,對它來說太重了。本來是「能呼叫工具」,最後變成「來不及呼叫工具」。
兩個模型都顯示:能力(模型支援 tool call)和行為(模型在這個 harness 下實際發 tool call)是兩件事——一邊是「決策被淹沒」、另一邊是「throughput 崩潰」,結果都沒觸發 completion gate。
因此,gate 是必要條件,但若要真的有效,還得確保模型在當時的負荷之下,還會(並且來得及)去碰它。
結語
這組實驗主要在表明:在同一個任務、同一份 prompt 下,改 completion gate 的位置,假性完成的發生率就會跟著變動。
以這次的註腳重排任務來說,當 workflow 的成敗開始取決於真實狀態、工具結果、驗證通過或錯誤恢復時,如果 completion gate 只停留在語言層,假性完成率高達 30–50%;當 completion gate 真正搬到外面的 checker,假性完成率則降到 0%。
這篇測的是一個有明確 checker、錯誤類型清楚、完成條件可外部檢查的任務,不是嚴格的 model benchmark。但結果已經夠直接了:Prompt engineering 可以改善表達與引導,但不會自動把控制責任做到位。
流程設計上,除了要把控制責任移出去,還得確認那個閘門在實際負荷下真的有人敲——沒人敲的閘門,跟沒有閘門差不多。
這就是 Claude 和 Codex 對這些失敗 case 給的提醒。
-
這裡選擇 Claude Code CLI 與 Codex CLI,而不是直接呼叫 LLM API,主要是因為本文要觀察的是比較接近實務使用的 agent workflow:它們會讀檔、寫檔、跑命令,也比較容易暴露「完成判定放在哪裡」這類控制問題。因此,這次只比較 agent CLI 在多步驟任務中的 workflow 行為。缺點是結果會受模型版本、權限設定與工作目錄狀態影響,所以比較適合把它當成 workflow control demo 來看。 ↩︎
-
順帶一提,在 Qwen3.5 出現之前,Ollama 建議跟 Claude Code 搭配的 Qwen3 模型,並不是
Qwen3:8b,而是qwen3-coder(30B-A3B MoE,agentic 後訓練變體)。Alibaba 並沒有提供小 dense 的 coder 版本——這個產品決策本身就間接承認:要在 agentic harness 裡可靠觸發 tool-use,光只有「模型支援 function calling」還不夠,還要相應的後訓練配上夠大的決策容量。 ↩︎