最近幾年,在微服務打滾的人,不時會遇到神祕的 “idempotency key” 字眼。本文爬梳 idempotency key 的技術背景,探討運作流程,並分析資料庫的實作選項。
Idempotency 冪等性
在 API 服務中,常常需要留意 idempotency(冪等性)。
名詞:idempotency,形容詞:idempotent。
“Idempotency” 這字眼源自數學。維基百科是這麼解釋 “idempotent function” 的:
idempotent elements are the functions f: E → E […] such that for all x in E, f(f(x)) = f(x)
如果套用到電腦界 1,idempotency 性質可以詮釋成:
- f:可以是 function 或是 API endpoint。
- x:可以是 argument 或是 API header & payload。
- 如果 f 是 idempotent,就代表:對 f(x) 執行 1 次產生的效果,與執行 N 次產生的效果,完全一樣。
譬如說,如果有一個管理商品庫存的服務:
type Item struct {/*...*/}
type ItemInventory interface {
func GetQuantity(item Item) int // 查詢庫存量
func SetQuantity(item Item, num int) // 設定庫存量
func DecreaseQuantity(item Item) // 庫存量減一
}
那麼,像以下這些動作,呼叫 1 次的效果,與呼叫 N 次的效果一樣,即可稱為是 idempotent:
var num int
// 查詢庫存量
num = inventory.GetQuantity(item)
num = inventory.GetQuantity(item)
num = inventory.GetQuantity(item)
//...
// 設定庫存量
num = 100
inventory.SetQuantity(item, num)
inventory.SetQuantity(item, num)
inventory.SetQuantity(item, num)
反之,像以下這些動作,呼叫 1 次的效果,與呼叫 N 次的效果會不一樣,即可稱為是 non-idempotent:
/*...*/ // 起初庫存量為 100
inventory.DecreaseQuantity(item) // 庫存量會變成 99
inventory.DecreaseQuantity(item) // 庫存量會變成 98
inventory.DecreaseQuantity(item) // 庫存量會變成 97
Non-idempotent 操作有必要存在嗎?
在 functional programming 思潮下,immutability 及 idempotency 似乎才是政治正確之舉。
Non-idempotent 的操作,真的有必要存在嗎?
譬如說,即使沒有 non-idempotent 的 DecreaseQuantity,我們仍可透過 idempotent 的 SetQuantity 來達到一樣的效果:
num = inventory.GetQuantity(item) // 起初庫存量為 100
numTarget := num - 1
inventory.SetQuantity(item, numTarget) // 庫存量會變成 99
numTarget--
inventory.SetQuantity(item, numTarget) // 庫存量會變成 98
numTarget--
inventory.SetQuantity(item, numTarget) // 庫存量會變成 97
如此一來,是否真的沒有必要再留下 non-idempotent 的 DecreaseQuantity?至少有兩件事需要思考:
-
語意層面的改變。原本
DecreaseQuantity的簽名,並沒有「庫存量」這一欄,也就是說,client 並不需要知道「目前庫存量」,即可進行「庫存量減一」。如果改寫成SetQuantity版本,簽名不同,多了「庫存量」欄位,換句話說,原本不必知道的「庫存量」內容,現在就必須透露出來了——這改變了原本「庫存量減一」的操作語意。 -
同步問題。同一時間,萬一有別人也在透過這個新方法改動「庫存量」,就會發生 race condition。
因此,某些時候,non-idempotency 可能無法完全迴避。
HTTP 的 idempotency 規範
HTTP 對於 idempotency 有一些規範。像 HTTP/1.1 的規格書 §9.1.2 就指出:
Methods can also have the property of “idempotence” in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request. The methods
GET,HEAD,PUTandDELETEshare this property. Also, the methodsOPTIONSandTRACESHOULD NOT have side effects, and so are inherently idempotent.
RFC 5789 也提到:
PATCHis neither safe nor idempotent as defined by RFC2616, Section 9.1.
所以,綜合來說,在 HTTP 的標準規範當中,只有 POST 及 PATCH 不是 idempotent。
對這些 HTTP 細節感興趣的,請參考 ihower 的〈HTTP Verbs:談 POST, PUT 和 PATCH 的應用〉一文。
Web API 的 idempotency 問題
前面的 Go 程式碼講的是 in process 場景。環境單純,沒有太多失敗、重試的未知狀況,不會有太大的 idempotency 問題。如果換成 out of process 場景,環境不再單純,網路環境不可靠,另一頭的通訊對象也不見得是穩定的,失敗、重試的未知狀況勢必增加,idempotency 就變成不得不去正視的議題。
譬如說,如果把管理商品庫存服務實作成 RESTful API:
Go + Gin 實作的 RESTful API 例子
import (
"github.com/gin-gonic/gin"
"strconv"
)
func main() {
//...
router := gin.Default()
// 查詢庫存量
router.GET("/inventory/quantity/:item_id", func(c *gin.Context) {
//...
num := inventory.GetQuantity(item)
//...
})
// 設定庫存量
router.PUT("/inventory/quantity/:item_id", func(c *gin.Context) {
//...
num, _ := strconv.Atoi(c.PostForm("num"))
inventory.SetQuantity(item, num)
//...
})
// 庫存量減一
router.POST("/inventory/quantity/:item_id/dec", func(c *gin.Context) {
//...
inventory.DecreaseQuantity(item)
///
})
router.Run()
}
對於原本就是 idempotent 的 GetQuantity 和 SetQuantity 操作來說,換成 RESTful 版本並沒什麼問題。像以下這個例子中,Client 在 🅐 步驟向 Server 呼叫 query quantity 操作時,只要該資料沒被別人改動到,這個 🅐 步驟不管重試多少次,得到的結果都會是一樣的。
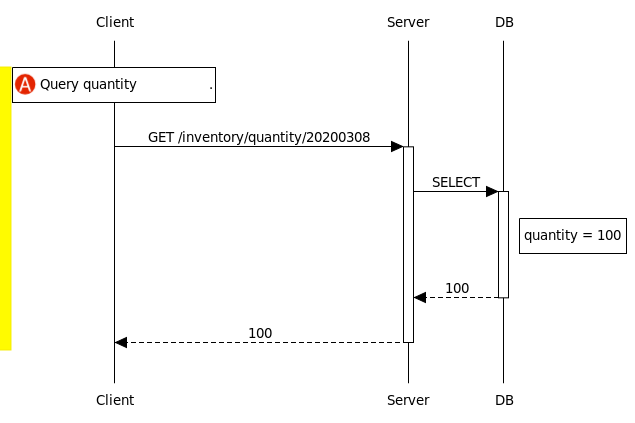
但是,對於原本就是 non-idempotent 的 DecreaseQuantity 操作來說,一遇到失敗、重試的未知狀況就麻煩了。像以下這個例子中,Client 在 🅑 步驟向 Server 呼叫 decrease quantity 操作時,Server 及 DB 都完成了各自的任務,可惜當 Server 在回傳結果給 Client 時,因為網路不穩定而漏失訊息。
Client 不會知道 🅑 背後涉及的各個環節究竟完成了多少,只會以為 🅑 步驟沒有生效,便主動以 🅑’ 步驟重試一次。Server 並不知道這個 🅑’ 只是個美麗的誤會,只能忠實地再執行一次 DecreaseQuantity 操作。於是,DecreaseQuantity 這個 non-idempotent 操作,就被錯誤地重複使用,造成錯誤的結果。
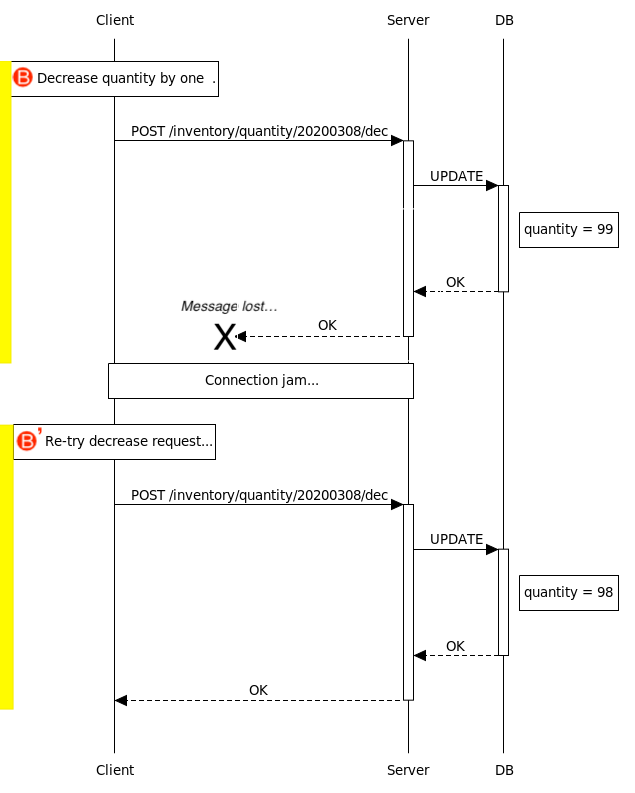
這也是為什麼我們在一些沒有仔細處理 idempotency 的交易網站上,會看到這類警語:
交易進行中,請勿按下【重新載入此頁】按鈕,以避免重複扣款。
也就是說,他們認為,倘若因為電腦或網路不穩定而頻頻手動重試,從而導致的任何不良後果,都是使用者不聽勸告的錯。
向 TCP 取經
在不穩定的分散式系統中,對於 non-idempotent 的操作,該如何避免重試所引發的問題?
不妨師法 TCP 吧,畢竟它算是在不可靠的 IP 傳輸環境中進行可靠傳輸的老祖宗了。
每一個 TCP segment 的 header 都帶有一個序列號 (seq),透過它,TCP 通訊的雙方,得以在不可靠的環境中,處理連線建立、流量控制、連線關閉等議題。2 就以 TCP 的 3-way handshake 機制為例,雙方藉由 seq 來溝通是否成功地傳送與接收訊息:

我們來分析 🅒 🅓 🅔 這幾種訊息丟失的狀況。
如果 🅒 訊息在中途就丟失了:
- 那麼,Server 自然不會送出 🅓。
- 既然 Client 遲遲沒收到 🅓,也就會繼續重試 🅒 (seq=x)。
如果 🅒 訊息成功送給 Server 了,但 🅓 訊息卻在中途就丟失了:
- 既然 Client 遲遲沒收到 🅓,就會繼續重試 🅒 (seq=x)。
- Server 在收到 🅒 時,會根據 seq=x 得知這是重複的訊息。
如果 🅔 訊息在中途就丟失了:
- 既然 Server 遲遲沒收到 🅔,就會繼續重試 🅓 (seq=y)。
- Client 在收到 🅓 時,會根據 seq=y 得知這是重複的訊息。
根據以上分析,我們可從 TCP 偷學一個祕訣:只要在 request 附上一個識別碼,就能讓通訊雙方偵測出失敗重試的情況,以採取對應的措施。
這就是 TCP 在 layer 4 進行的可靠傳輸措施。
識別碼,由誰來產生?
這一招,不僅在 layer 4 行之有年,在 layer 7 也一樣管用。
接下來的問題是:識別碼,由誰來產生?由 request 的接收方,還是發起方?
識別碼可以由 request 接收方:server 產生。像 Restful Web Services Cookbook §10.8 & §10.9 就建議,針對 non-idempotent 的操作,server 可先產生 nonce 當作識別碼,將它當成參數添加到服務的 URI 上面,再請 client 透過這個加過料的 URI 來操作 server 的服務。
也有人把識別碼的生成責任交給 request 發起方:client 來做。像 Stripe 官方提供的 StripeClient 程式庫,針對 POST 及 DELETE 類型的操作,會先在 client 這邊產生 uuid v4 當作識別碼,將它添加到 HTTP header 中(此例為 Idempotency-Key),再傳給 server:
# It is only safe to retry network failures on post and delete
# requests if we add an Idempotency-Key header
if %i[post delete].include?(method) && Stripe.max_network_retries > 0
headers["Idempotency-Key"] ||= SecureRandom.uuid
end
簡單的概念,近年來較新的服務,尤其是與金流或電子商務有關的,似乎也很流行這種 “idempotency key” 手法:
- Adyen: API idempotency
- Airbnb: Avoiding Double Payments in a Distributed Payments System
- Square: Working with APIs: Idempotency
- Stitch Fix: Patterns of Service-oriented Architecture: Idempotency Key
- Stripe:API Reference: Idempotent Requests
概念很簡單,卻有個來歷不明的酷炫名詞 “idempotency key”。根據 Stripe 工程師 Brandur Leach 在 “Implementing Stripe-like Idempotency Keys in Postgres” 一文所說,這名詞是 Stripe 發明的:
An idempotency key is a unique value that’s generated by a client and sent to an API along with a request. The server stores the key to use for bookkeeping the status of that request on its end. If a request should fail partway through, the client retries with the same idempotency key value, and the server uses it to look up the request’s state and continue from where it left off. The name “idempotency key” comes from Stripe’s API.
在沒有進一步翻案證據之前,暫時姑且接受「這是 Stripe 發明的」的說法吧。
Idempotency key 的生成
理論上,任何機制,只要在合理範圍內具有唯一性,就能用來產生 idempotency key。
但實務上,在實作 idempotency key 時,可能還需要考慮幾個議題:
-
由資料庫自動產生,還是由程式邏輯層產生?
-
純亂數,還是單調遞增?
資料庫能夠自動替我們產生單調遞增序號。只要將 idempotency key 宣告成 MySQL 的 auto_increment 或 PostgreSQL 的 serial 之類的資料型態,再搭配像 MySQL 的 last_insert_id() 或 PostgreSQL 的 insert returning 之類的查詢語法,即可一次搞定 idempotency key 生成與儲存。
乍看之下很方便,不過,如果資料庫有分庫分表,就需要再額外處理,才能確保序號的唯一性。另一個或許更嚴重的缺點是,從架構潔癖的角度來看,違反了 clean architecture 的分層原則與相依原則:
資料庫是個細節,我們將這些東西放在外頭,在那邊它們不會有什麼危害。
資料庫不是資料模型。資料庫是一塊軟體,是提供對於資料存取的工具。它是一個低層級的細節——是一種機制。一名好的架構師,不會允許底層機制污染系統的架構。
同樣有架構潔癖的 DDD,也不喜歡過於仰賴資料庫機制,像 Implementing Domain-Driven Design 的 §5.2 就直接建議大家將序號產生機制放在 Repository 層。3
如果要改由程式邏輯層產生 idempotency key,可能會直接套用 uuid,甚至訴諸 Snowflake、Sonyflake、Leaf 這類分散式 ID 服務。不依賴資料庫,彈性大,也符合架構潔癖。
不依賴資料庫,符合了架構潔癖,是否會因此犧牲了資料庫的效能?接下來我們就來探討這議題。
Idempotency key 的儲存
透過程式邏輯產生的 id,可粗分為三大類:
這些 idempotency key 該如何儲存,才可與資料庫內建的單調遞增序號一較高下?
理論上來說,在目前資料庫系統主流的 B+ tree 索引結構下,單調遞增的數值,會比純亂數來得有效率。因此,若不計資料欄位大小差異,三者的存取效率,理論上應該會是 Snowflake > uuid v1 > uuid v4。
不過,我對於 PostgreSQL 提供的 uuid 資料型態格外感興趣:
PostgreSQL provides storage and comparison functions for UUIDs, but the core database does not include any function for generating UUIDs, because no single algorithm is well suited for every application.
從 PostgreSQL 原始碼 uuid.h 及 uuid.c 來看,骨子裡是用 16 bytes 字元陣列來實作:
/* uuid size in bytes */
#define UUID_LEN 16
typedef struct pg_uuid_t
{
unsigned char data[UUID_LEN];
} pg_uuid_t;
/* internal uuid compare function */
static int
uuid_internal_cmp(const pg_uuid_t *arg1, const pg_uuid_t *arg2)
{
return memcmp(arg1->data, arg2->data, UUID_LEN);
}
/* hash index support */
Datum
uuid_hash(PG_FUNCTION_ARGS)
{
pg_uuid_t *key = PG_GETARG_UUID_P(0);
return hash_any(key->data, UUID_LEN);
}
對於 uuid 的存取性能,PostgreSQL 似乎是有備而來胸有成竹。
因此,我針對 PostgreSQL 的 uuid 資料型態,分別實驗「亂數」與「遞增數值」存取效率,順便也拿 bigint 做對照組,看看這些排列組合,哪一種比較適合 idempotency key 用途:
| Idempotency Key 類型 | 演算法 | 資料大小 (bytes) | PostgreSQL 資料型態 |
|---|---|---|---|
| 亂數 | uuid v4 | 16 | uuid |
| 遞增數值 | uuid v1 | 16 | uuid |
| 遞增數值 | Snowflake | 8 | bigint |
針對這些排列組合,我進行三組實驗:
- 寫入 N 筆資料:InsertUuidV1、InsertUuidV4、InsertSnowflake
- 隨機存取 10% 資料,無 DB cache:SelectUuidV1/clean、InsertUuidV4/clean、InsertSnowflake/clean
- 隨機存取 10% 資料,有 DB cache:SelectUuidV1/cache、InsertUuidV4/cache、InsertSnowflake/cache
實驗程式放在 https://github.com/William-Yeh/idempotency-key-test
我的實驗環境:
- MacBook Pro
- CPU: 2.8 GHz 四核心Intel Core i7
- Go: 1.14
- PostgreSQL: 12.2
首先牛刀小試一下,實驗 10 萬筆資料:
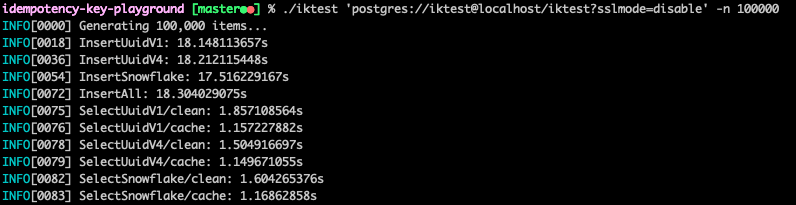
乍看之下,三種 idempotency key 資料類型,彼此性能差異並不大。數量級分別是:
- 寫入 N 筆資料:每秒能處理約 5*10³ 筆操作。
- 隨機存取 10% 資料,無 DB cache:每秒能處理約 5*10⁴ 筆操作。
- 隨機存取 10% 資料,有 DB cache:每秒能處理約 8*10⁴ 筆操作。
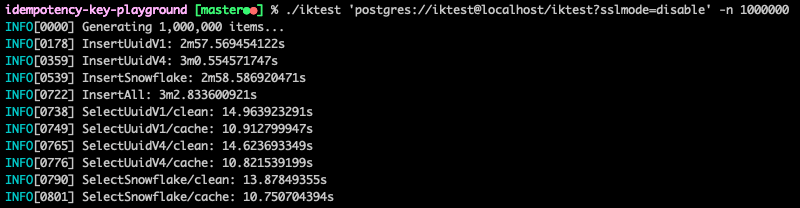
放大十倍試試看,實驗 100 萬筆資料:
最後,實驗 300 萬筆資料,順便看看三種 idempotency key 資料類型佔用的索引空間:
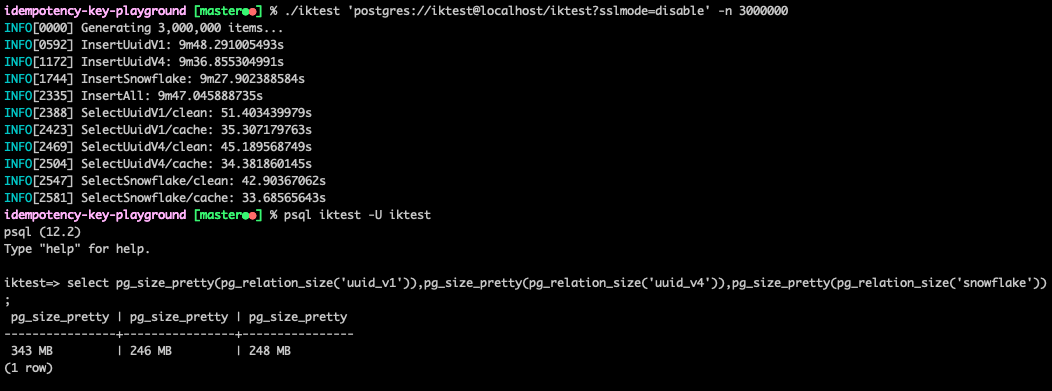
執行速度差異不大。至於索引結構,則是 uuid v1 顯著偏高,而 uuid v4 與 snowflake 無太大差異。
綜合以上實驗,PostgreSQL 的 uuid 效能十分優異,足堪大任。我建議:如果你的 idempotency key 想要是亂數,可以直接把 uuid v4 存在 uuid 欄位中;如果你的 idempotency key 想要是單調遞增數值,不妨考慮把 snowflake 存在 bigint 欄位中。
如果你用的是其他資料庫系統,此處的建議不見得適用,請自行實驗。
致謝
實驗設計過程中,從 Carousell 同事得到許多建議,特此致謝。
-
嚴格來說,電腦領域講的 “idempotency”,已經與數學領域講的 “idempotency” 不盡相同了,可說是一種假借。詳情請見維基百科的說明: https://en.wikipedia.org/wiki/Idempotence#Computer_science_meaning ↩︎
-
對於 TCP 序列號機制感興趣的,可參考鄭中勝寫的三篇介紹文章:〈TCP 序列號 (Sequence Number, SEQ)〉、〈TCP 三向交握 (Three-way Handshake)〉、〈TCP 流量控制 (Flow Control)〉。 ↩︎
-
在 DDD 中,id 生成機制很適合放在 Repository 層。如果你沒有 Implementing Domain-Driven Design 這本書,也可以參考劉鳳軒寫的〈DDD 戰術設計:Entity 概念與實作〉一文。 ↩︎